Using resources effectively
Overview
Teaching: 20 min
Exercises: 25 minQuestions
What are the different types of parallelism?
How do we execute a task in parallel?
What benefits arise from parallel execution?
What are the limits of gains from execution in parallel?
Objectives
Prepare a job submission script for the parallel executable.
Launch jobs with parallel execution.
Record and summarize the timing and accuracy of jobs.
Describe the relationship between job parallelism and performance.
We now have the full toolset we need to run a job, and we’re going to learn how to scale up our job performance using parallelism. This is a very important aspect of HPC systems, as parallelism is one of the primary tools we have to improve the performance of computational tasks.
In this lesson, we will learn about three ways to parallelize a problem: embarrassingly parallel, shared memory parallelism, and distributed parallelism.
Infinite Monkey Theorem
The infinite monkey theorem states that a monkey hitting keys independently and at random on a typewriter keyboard for an infinite amount of time will almost surely type any given text, including the complete works of William Shakespeare.

We don’t have infinite time or resources, but we can simulate this problem with A LOT of monkeys.
Create the following script to simulate a “monkey”. Let’s name this monkey.py:
#!/usr/bin/env python3
import random
import string
nwords = 100
minlen = 2
maxlen = 10
dictionaryfile = "wordlist.txt"
# Generate random string of character of certain length
def randomchars(length):
return "".join([
random.choice(string.ascii_lowercase) for _ in range(length)
])
# Create a list of random character strings with range of lengths randomly
# distributed between minlen and maxlen
wordlist = [
randomchars(random.choice(range(minlen,maxlen))) for i in range(nwords)
]
# Read the words from our downloaded dictionary
with open(dictionaryfile, "r") as f:
englishwords = [ line.strip() for line in f ]
# Print all the randomly generated "words" that are also in the dictionary
for word in wordlist:
if word in englishwords:
print(word)
Let your monkey loose on a compute code
Create a submission file, requesting one task on a single node, then launch it.
[yourUsername@borah-login ~]$ nano monkey-job.sh
[yourUsername@borah-login ~]$ cat monkey-job.sh
#!/usr/bin/env bash
#SBATCH -J monkey
#SBATCH -p short
#SBATCH -N 1
#SBATCH -n 1
# Load the computing environment we need
module load python/3.9.7
# Execute the task
python ./monkey.py
[yourUsername@borah-login ~]$ sbatch monkey-job.sh
As before, use the Slurm status commands to check whether your job is running and when it ends:
[yourUsername@borah-login ~]$ squeue --me
Use ls to locate the output file. The -t flag sorts in
reverse-chronological order: newest first. What was the output?
Read the Job Output
The cluster output should be written to a file in the folder you launched the job from. For example,
[yourUsername@borah-login ~]$ ls -tslurm-2114623.out monkey-job.sh monkey.py wordlist.txt[yourUsername@borah-login ~]$ cat slurm-2114623.outwow ld ax tk bl kgYour monkey no doubt came up with a different list of words.
Now we have our single “monkey” how can we scale this up using a compute cluster?
Running multiple jobs at once
This is an example of an embarassingly parallel problem: Each monkey doesn’t need to know anything about what the other monkeys are doing. So if our goal is for the monkeys to generate the most words, more monkeys is the solution.
By making the following modification to our submission script (monkey-job.sh),
we can use a job array to put multiple monkeys to work!
#!/usr/bin/env bash
#SBATCH -J monkey
#SBATCH -p short
#SBATCH --array=0-10
#SBATCH -N 1
#SBATCH -n 1
# Load the computing environment we need
module load python/3.9.7
# Execute the task
python ./monkey.py
After modifying your submission script, resubmit your job:
[yourUsername@borah-login ~]$ sbatch monkey-job.sh
You can check on your job while it’s running using:
[yourUsername@borah-login ~]$ squeue --me
Or see the time, hostname, and exitcode of finished jobs using:
[yourUsername@borah-login ~]$ sacct -X
Once your job is finished, we can use the word count program, wc, to see how
many words were generated by our array of monkeys:
[yourUsername@borah-login ~]$ wc -l slurm-2114626_*
8 slurm-2114626_0.out
2 slurm-2114626_10.out
6 slurm-2114626_1.out
4 slurm-2114626_2.out
7 slurm-2114626_3.out
11 slurm-2114626_4.out
8 slurm-2114626_5.out
4 slurm-2114626_6.out
4 slurm-2114626_7.out
5 slurm-2114626_8.out
10 slurm-2114626_9.out
69 total
By using a job array, we were able to increase our word output with no changes to our code and a single change to our submission script. Next we’ll learn about more complex types of parallelism.
Distributed vs shared memory parallelism
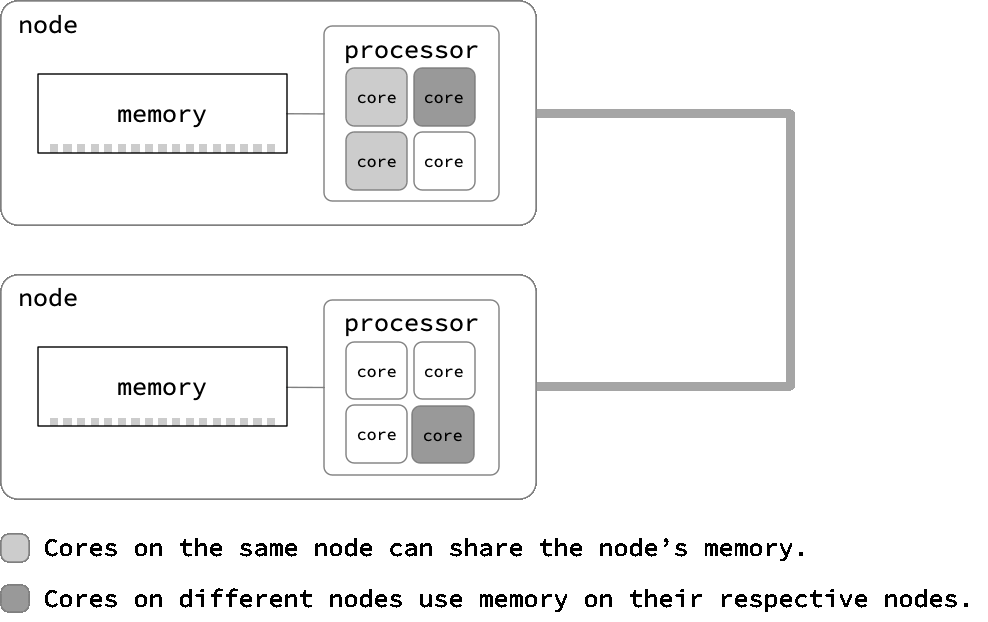
Hands on activity
To demonstrate the difference between these types of parallelism, your instructor will lead you through an activity.
Takeaway
Shared memory parallelism requires workers to be able to access the same information. In the puzzle example, the people working together at the same table can reach the same pieces. In the HPC world, shared memory parallelism can be used on a single compute node, where the CPU cores can access the same memory.
Distributed memory parallelism requires a communication framework to give a task to and collect output from each worker. In the puzzle example, people seated at different tables must have someone bring them pieces, take the pieces back, and organize the partial results. In the HPC world, a framework called MPI allows workers across multiple nodes to communicate over a specialized network.
Choosing the right parameters for your SLURM job
When submitting jobs to SLURM, choosing the right combination of --ntasks and
--cpus-per-task depends on understanding how your program implements
parallelism.
--ntasks specifies the number of separate processes with independent memory
spaces. Each task runs as a distinct process that cannot directly access
another task’s memory. This maps to distributed memory parallelism, where
processes communicate through message passing (like MPI). Use --ntasks when
your program:
- Uses MPI (
mpirun -n 4 your_program) - Runs multiple independent instances
- Needs processes that communicate via networks or files
--cpus-per-task specifies how many CPU cores each task can use through
threads that share the same memory space. This maps to shared memory
parallelism, where threads within a process can directly access the same
variables and data structures. Use --cpus-per-task when your program:
- Uses OpenMP (
export OMP_NUM_THREADS=8) - Uses threading libraries (pthread, tbb, omp)
- Parallelizes loops with shared data structures
Giving your job more resources doesn’t necessarily mean it will have better performance. It’s important to evaluate what kind of parallelization your program can use and tailor your resource request to fit. To learn more about parallelization, see the parallel novice lesson lesson and the Cornell Virtual Workshop on Parallel Programming Concepts and High Performance Computing.
Key Points
Parallel programming allows applications to take advantage of parallel hardware.
The queuing system facilitates executing parallel tasks.
Some performance improvements from parallel execution do not scale linearly.